

介绍一下我自己已经用了三年多的 Nix S3 Binary Cache 的实现方案和思路。
特色:
- 土制灵车
- 极低成本:使用 Cloudflare R2 等有免费额度的 S3 服务,每月 0 USD 免费用
- 几乎 Serverless:稳定,高性能,无服务器瓶颈
- 极佳兼容性:使用
nix copy直接上传
注:第一点与其他特色并没有冲突。
本文所有命令都使用实验性的 Nix CLI v3,需开启 experimental-features = nix-command flakes。
⚓ 最简单的 Nix S3 Binary Cache
在 Nix 中,S3 binary cache 也是一种 store。它的 store URL 形如 s3://BUCKET_NAME。文档见 Nix Manual - S3 Binary Cache Store。
如果不是 AWS S3,而是其他兼容 S3 API 的存储服务,比如 Cloudflare R2、Backblaze B2、以及 MinIO 等,可以在 store URL 中通过 query 字符串指定 endpoint:s3://BUCKET_NAME?endpoint=ENDPOINT_URL。
Nix 使用官方的 AWS SDK 来访问 S3 存储服务,因此它支持的认证方式和 AWS SDK 支持的认证方式是一致的。常见的认证方式包括环境变量 AWS_ACCESS_KEY_ID 和 AWS_SECRET_ACCESS_KEY,以及使用 ~/.aws/credentials 文件等。
因此,最简单的 Nix S3 binary cache 的使用方式,就是准备一个 S3 兼容的 bucket,然后设置好认证信息,然后直接使用 nix copy:
export AWS_ACCESS_KEY_ID="..."
export AWS_SECRET_ACCESS_KEY="..."
export AWS_EC2_METADATA_DISABLED=true # 如果你用的不是 AWS
nix copy "nixpkgs#hello" --to "s3://$BUCKET_NAME?endpoint=$ENDPOINT_URL"这样就把 nixpkgs#hello 上传到 bucket 中了。
⚓ 签名
这样的 binary cache 无法正常使用,因为我们没有对上传到的内容做签名。要对 store path 做签名,可以使用 nix store sign 命令:
nix store sign "nixpkgs#hello" --recursive --key-file "$SECRET_KEY_FILE"
# 本地签名后再上传到 binary cache
nix copy "nixpkgs#hello" --to "s3://$BUCKET_NAME?endpoint=$ENDPOINT_URL"这样就会对 nixpkgs#hello 以及它的所有依赖做签名。签名信息会存储在本地的 Nix store 中。
要生成签名密钥,可以使用 nix key generate-secret 命令:
nix key generate-secret --key-name "$KEY_NAME"该命令会生成一个私钥,输出到 stdout,将它妥善保管。
生成私钥后,使用 nix key convert-secret-to-public 命令导出公钥:
cat "$SECRET_KEY_FILE" | nix key convert-secret-to-public获得的公钥形如(这是我的 cache 的公钥):
cache.li7g.com:YIVuYf8AjnOc5oncjClmtM19RaAZfOKLFFyZUpOrfqM=⚓ 使用
要使用这个 binary cache,为 Nix 配置 binary cache 的 HTTP URL 和公钥。分别位于 nix.conf 的 substituters 和 trusted-public-keys 选项中。别忘了使得 S3 bucket 能通过 HTTP URL 被公开访问。
⚓ 我的配置
我使用公开的 Cloudflare R2 作为存储,设置了自定义域名 cache.li7g.com,并配置好写入使用的 token:
resource "cloudflare_r2_bucket" "cache" {
account_id = local.cloudflare_main_account_id
name = "cache-li7g-com"
location = "APAC" # Asia Pacific
storage_class = "Standard"
}
resource "cloudflare_r2_custom_domain" "cache" {
account_id = local.cloudflare_main_account_id
enabled = true
bucket_name = cloudflare_r2_bucket.cache.name
domain = "cache.${cloudflare_zone.com_li7g.name}"
zone_id = cloudflare_zone.com_li7g.id
}
resource "cloudflare_api_token" "cache" {
name = "cache"
status = "active"
policies = [{
effect = "allow"
permission_groups = [
{ id = local.permissions_groups_map["Workers R2 Storage Bucket Item Write"] }
]
resources = jsonencode({
"com.cloudflare.edge.r2.bucket.${local.cloudflare_main_account_id}_default_${cloudflare_r2_bucket.cache.name}" : "*"
})
}]
}使用时,只需要做如下设置:
{
nix.settings = {
substituters = [ "https://cache.li7g.com" ];
trusted-public-keys = [
"cache.li7g.com:YIVuYf8AjnOc5oncjClmtM19RaAZfOKLFFyZUpOrfqM="
];
};
}⚓ 忽略上游已有内容
nix copy 命令上传时,并不会考虑 cache.nixos.org 中是否已经有了相同内容的问题。
这意味着我们要花钱存完全没必要存储的内容,无法接受。
查看我的主力机的 closure 大小:
$ nix path-info /run/current-system --closure-size --human-readable
/nix/store/7rx2223cw2lbhzhnyd77r9k81xs4blrn-nixos-system-parrot-26.05.20260121.88d3861 35.5 GiB35.5GiB,可以看到,已经远超 Cloudflare R2 和 Backblaze B2 的免费额度(10GB)。
⚓
nix copy 的行为
nix copy 命令在上传时,会先检查目标 binary cache 中是否已经有了相同的内容。如果有,就不会重复上传。
检查方式是对 narinfo 发送 S3 GetObject 请求:
- 例如一个 store path 是
/nix/store/i3zw7h6pg3n9r5i63iyqxrapa70i4v5w-hello-2.12.2。 - 它的
narinfo文件名就是i3zw7h6pg3n9r5i63iyqxrapa70i4v5w.narinfo。 nix copy会通过GetObject检查 cache 中是否有这个narinfo文件。
如果我们能迷惑 nix copy,从上游 cache 把 narinfo 文件“偷”过来,就能避免重复上传。
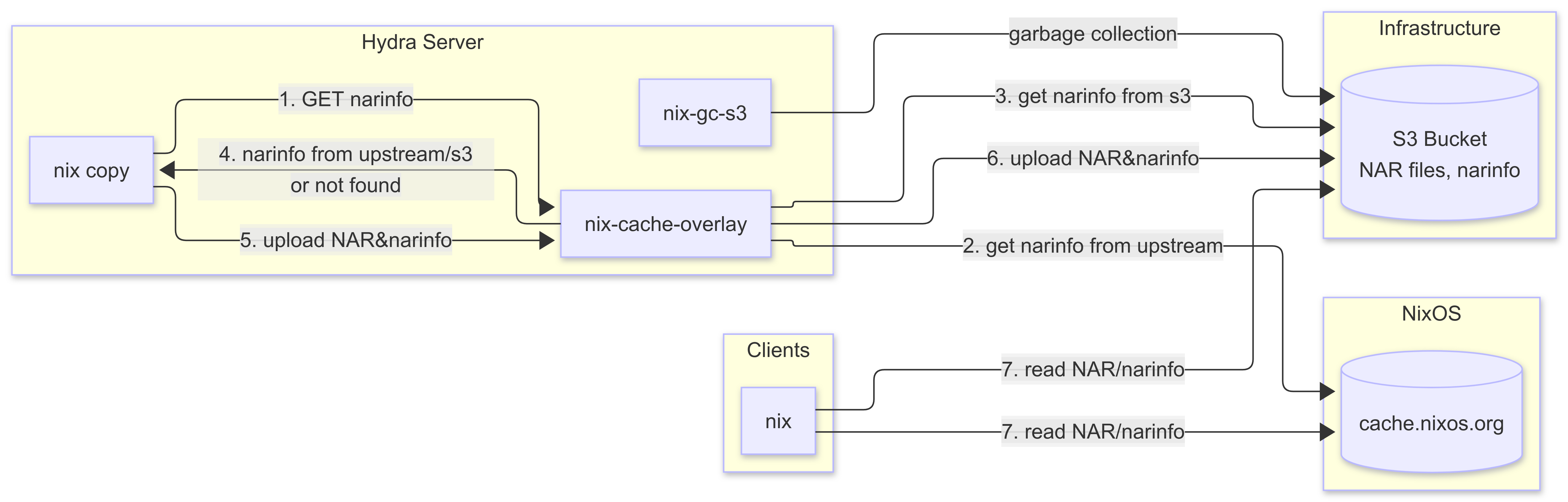
⚓ nix-cache-overlay
在以前我使用 nginx 配置 + aws-s3-reverse-proxy 来做这个事情,但由于 aws-s3-reverse-proxy 使用 SigV4 认证请求,并且中间过了好多代理,涉及到 Host header 的变化,导致调试非常麻烦。这是真正的灵车,感兴趣的可以看一看我之前的配置。
终于有一天我的原始方案彻底挂了,我看了半天都没看明白为什么 aws-s3-reverse-proxy 算出来的签名和 nix copy 算出来的不一样。
所以我最近写了一个 nix-cache-overlay 专门来做这件事。nix-cache-overlay 是一个非常轻量的代理服务器,只做这么两件事:
- 把对
/BUCKET_NAME/*.narinfo的GET/HEAD请求的路径改写成/*.narinfo,然后转发到上游 binary cache,如果返回 200,把响应返回给客户端;如果返回 404,尝试下一个上游。 - 把所有上游尝试完毕都 404 后,对请求做认证,成功后把请求签上 SigV4 签名,转发到 S3 存储服务。
认证部分直接忽略签名,把客户端提供的 AWS_ACCESS_KEY_ID 当成一个 token 来使用。因此不容易在中间代理过程中出错,代价是降低了一些安全性。
由于 nix-cache-overlay 直接转发请求,因此可以直接支持 S3 multipart 上传:
使用方法就是首先起一个 nix-cache-overlay 服务(添加 overlay 和 NixOS module 后):
{
services.nix-cache-overlay = {
enable = true;
listen = "[::1]:8080";
endpoint = "https://host.of.s3.endpoint";
environmentFile = /path/to/env/file;
};
}environmentFile 中需要存储 token 和用于连接到 S3 的 credential:
AWS_ACCESS_KEY_ID=...
AWS_SECRET_ACCESS_KEY=...
AWS_EC2_METADATA_DISABLED=true
NIX_CACHE_OVERLAY_TOKEN=...让 nix copy 使用 nix-cache-overlay,只需要把 binary cache 的 endpoint 指向 overlay,并配置 token 到 AWS_ACCESS_KEY_ID 即可:
export AWS_ACCESS_KEY_ID="$NIX_CACHE_OVERLAY_TOKEN" # 不再使用 S3 的 access key
export AWS_SECRET_ACCESS_KEY="-" # 不需要 secret key,只根据 key id 做认证
export AWS_EC2_METADATA_DISABLED=true
nix store sign "nixpkgs#hello" --recursive --key-file "$SECRET_KEY_FILE"
nix copy "nixpkgs#hello" --to "s3://$BUCKET_NAME?endpoint=http://[::1]:8080"注意,nix copy 对 narinfo 查询的并发非常恐怖,因此建议把 overlay 服务直接部署在本地机器上,并且不要通过反向代理服务器访问 overlay 服务。
反向代理服务器的连接数可能被打满,导致 nix copy 收到一堆 500 然后挂掉。
Jan 22 23:30:21 nuc nginx[85266]: 2026/01/22 23:30:21 [alert] 85266#85266: 512 worker_connections are not enough
Jan 22 23:30:21 nuc nginx[85266]: 2026/01/22 23:30:21 [alert] 85266#85266: *554 512 worker_connections are not enough while connecting to upstream, client: 100.95.57.26, server: cache-overlay.*, reque>
Jan 22 23:30:21 nuc nginx[85266]: 2026/01/22 23:30:21 [alert] 85266#85266: *554 512 worker_connections are not enough while connecting to upstream, client: 100.95.57.26, server: cache-overlay.*, reque>
Jan 22 23:30:21 nuc nginx[85266]: 2026/01/22 23:30:21 [alert] 85266#85266: 512 worker_connections are not enough
Jan 22 23:30:21 nuc nginx[85266]: 2026/01/22 23:30:21 [alert] 85266#85266: *554 512 worker_connections are not enough while connecting to upstream, client: 100.95.57.26, server: cache-overlay.*, reque>
Jan 22 23:30:21 nuc nginx[85266]: 2026/01/22 23:30:21 [alert] 85266#85266: *554 512 worker_connections are not enough while connecting to upstream, client: 100.95.57.26, server: cache-overlay.*, reque>
Jan 22 23:30:21 nuc nginx[85266]: 2026/01/22 23:30:21 [alert] 85266#85266: 512 worker_connections are not enough⚓ 我的配置
通过使用 nix-cache-overlay,我只需要不到 4GiB 的 R2 存储空间,就能缓存我所有机器的 closure。
$ mc du r2-cache/cache-li7g-com
3.2GiB 12629 objects cache-li7g-com⚓ GC
Nix S3 binary cache 本身并不支持 GC,这也是一大痛点。 因此需要我们自己实现 GC 机制。
对 binary cache 进行 GC 其实分为两部分:
- 管理 GC roots
- 根据 GC roots 进行 GC
⚓ 管理 GC roots
许多人比较随意地向 binary cache push 内容,然后并不记录他们 push 的是什么东西,要保留多久。我个人对这种用法的 binary cache 直接使用 cachix,因为 cachix 提供了自动 GC 的功能。
而我自己建立的 S3 cache 则只存储我的 hydra CI 构建出来的内容。Hydra 其实提供了一个目录,里面存储了所有的 GC roots。如果你注意过 hydra 的 job 的配置的话,你会发现里面有一项叫作 "Number of evaluations to keep"。Hydra 会根据这个数字来决定保留多少个 evaluation 作为 GC roots。
所以我的方案就是使用 hydra 提供的 GC roots,来作为 binary cache 的 GC roots。
⚓ 根据 GC roots 进行 GC
这也是一大难点,因为我们不是在内存里,而是在 S3 上存储内容。显然我们不太能做各种 copying GC,那么就做 tracing GC 吧。
但是做 tracing GC 意味着还需要解析 narinfo 文件,获得它的依赖列表,然后递归地找到所有可达的其他 narinfo。S3 上的请求延迟会比较高,因此这个过程会比较耗时。
一个典型的 narinfo 文件内容:
StorePath: /nix/store/i3zw7h6pg3n9r5i63iyqxrapa70i4v5w-hello-2.12.2
URL: nar/0jra6lgdxfkivpxgr8vlfp7ccypy7a6g48jma9v2vps50xy13hn7.nar.xz
Compression: xz
FileHash: sha256:0jra6lgdxfkivpxgr8vlfp7ccypy7a6g48jma9v2vps50xy13hn7
FileSize: 57600
NarHash: sha256:1m4yy5hgxm1445f005fdqdm6ky6h2pdwy80kck9c4pvy9n6vbabx
NarSize: 274568
References: i3zw7h6pg3n9r5i63iyqxrapa70i4v5w-hello-2.12.2 j193mfi0f921y0kfs8vjc1znnr45isp0-glibc-2.40-66
Deriver: bkhfq83jwis7h9wak3h0kz0cv1r7xfnq-hello-2.12.2.drv
Sig: cache.nixos.org-1:K25JMfP03adJ85zC7xg8qLa2LEjK7edYMZ+JzZyaZTuKYL6EXDoPXFWaMnw/1Dlmz5/vvjILYOonkyG/fwMPDg==由于我的主要使用场景是存储 hydra 构建的内容,因此所有 closure 中的 store path 本地其实都有。所以,我的选择是直接在本地对 store path 调用 nix-store --query --requisites 来判断依赖关系,而不是下载并解析 narinfo 文件(也许直接让 nix 做递归查询会更好,快很多,不过我之前没有那样写)。这种做法其实比较局限,它要求 binary cache 中的内容必须在本地都有,但对于我的使用场景来说,这个要求是可以接受的。
知道哪些 narinfo 文件是需要保留的之后,根据其中的 URL 字段判断哪些 nar 文件是需要保留的。nar 文件的文件名其实是它自己的 hash,因此多个 narinfo 文件可能会引用同一个 nar 文件,因此这一步需要逐个下载所有要保留的 narinfo 文件。
最后调用 S3 API 把不需要保留的 narinfo 和 nar 文件删除掉即可,一次 API call 可以删除多达 1000 个对象,因此这一步其实并不耗时。
我写了一个 Python 脚本来做这件事,代码见 linyinfeng/nix-gc-s3。
⚓ 我的配置
我配置了一个 systemd 服务对 S3 cache 每晚执行一次 GC,服务内容其实就是调用一次 nix-gc-s3 脚本。
但这里仍然有需要注意的事项:nix-gc-s3 和 nix copy 不应该同时运行,所以我只在固定的 systemd 服务中运行 nix-gc-s3 和 nix copy,并且用 flock 加了互斥锁。
⚓ 结语
通过以上配置,我已经使用了三年多的 Nix S3 binary cache,成本极低(目前每月账单都是 0 USD),且不论是上传还是下载的性能都远超需要中间服务器的方案,如 attic。
但该方案也是一个土制方案:
- 没有基于时间的 GC,必须自己维护 GC roots
- GC 机制要求 binary cache 中的内容必须在本地都有
- 没有统一的工具管理上传和 GC,必须在
nix copy和nix-gc-s3时手动加锁
这些缺点限制了这个方案基本上只能和 hydra CI 结合使用,但对于我个人的使用场景来说,这已经足够了。
如果需要没有以上缺点的,能实现基于时间 GC 的方案,可以考虑使用 niks3。
最后介绍一下我个人的使用场景:
我用这个 cache 存储我所有机器的 closure,一旦某个机器,比如 fsn0 的 closure 成功上传到 cache,
我的 dotfiles 仓库的一个分支 nixos-tested-fsn0 就会指向构建出这个 closure 的 revision。
每天凌晨,fsn0 就会自动更新到 github:linyinfeng/dotfiles/nixos-tested-fsn0,并按需重启。
配合 flake.lock 的自动更新,各种监控,报警,我能用最少的精力维护我的服务器(大部分时候不需要投入任何精力)。
⚓ 一件趣事
我的博客也是用 Nix 构建的,我的 CI 会检查博客文件是否自包含,即不依赖 /nix/store。
- name: Check self-contained
run: |
[ $(nix path-info --recursive ./result | wc -l) == "1" ]写完这篇文章后发现这个检查失败了,原因是文中包含了一个 narinfo 文件,其中 References: 中有 glibc 的 store path:
j193mfi0f921y0kfs8vjc1znnr45isp0-glibc-2.40-66这是因为 Nix 检查运行时依赖的方法是。只要产物中包含某个编译期依赖的 hash,比如此处的 j193mfi0f921y0kfs8vjc1znnr45isp0,这个编译期依赖就会被认为是一个运行时依赖。
解决方法就是把 hash 的最后一位手动修改为 0 了。